この記事はBigQuery Advent Calendar 2020の14日目の記事です
もともとTogglのデータをAPIから引っ張ってきてBigQueryに入れているのでそのデータを使って今スプリントの消化時間の着地想定を計算するクエリを書いてみた
背景
※自分はチームに専任というわけではなく週○時間このプロジェクトに時間を使いますという調整をしてスプリントに参加させてもらっている
完全に自分の管理能力の問題なのだが週によって処分時間が変わってしまうことが多く、次の週やることの計画が立てづらいという課題があったので、毎日どのくらい時間を使っているかレポートを出すことで調整できるように今回のような試作を行った
Togglのデータ
TogglのAPIレスポンスをそのまま保存している
APIについては下記
toggl_api_docs/reports.md at master · toggl/toggl_api_docs
記事用に簡略化したデータを用意する
| start | project | description | dur | tags |
|---|---|---|---|---|
| 2020-11-17 15:01:16 UTC | 作業 | ○のコード化 | 3470000 | "["ProjectA"]" |
| 2020-11-24 14:16:28 UTC | 会議 | 質問会 | 2654000 | "["ProjectB"]" |
| 2020-11-10 09:16:54 UTC | 作業 | ○のコード化 | 906000 | "["ProjectA"]" |
| 2020-11-09 10:00:39 UTC | 作業 | ○のコード化 | 7178000 | "["ProjectA"]" |
| 2020-11-16 12:01:10 UTC | 会議 | DS | 2675000 | "["ProjectA"]" |
| 2020-11-04 18:36:27 UTC | 作業 | △の開発 | 2460000 | "["ProjectB"]" |
| 2020-11-02 15:08:15 UTC | 作業 | ○の調査 | 1931000 | "["ProjectC"]" |
| 2020-11-16 16:01:05 UTC | 会議 | バックログ確認 | 3553000 | "["ProjectA"]" |
| 2020-11-13 18:01:12 UTC | モブレビュー | コードレビュー | 3597000 | "["ProjectC"]" |
| 2020-11-11 15:10:40 UTC | 会議 | 相談 | 2952000 | "["ProjectA"]" |
| 2020-11-10 11:01:41 UTC | 会議 | 定例 | 2944000 | "["Div"]" |
| 2020-11-25 19:07:44 UTC | 会議 | レビュー | 1908000 | "["ProjectA"]" |
| 2020-11-10 13:03:48 UTC | 休憩 | お昼 | 3372000 | [] |
こんな感じのデータがあるっていうのが伝わればOKな感じのデータ
SQLの生成方法
日付やプロジェクトIDは実行時にenvsubstコマンドで環境変数から読み込んだものを差し替えたSQLを生成し実行しているので${GCP_PROJECT_ID}というような書き方になっている
export GCP_PROJECT_ID=hogehoge
export START_DATE=$(date -d "last thursday" +"%Y-%m-%d")
cat daily-work.sql | envsubst > /tmp/daily-work.sql
json=$(bq query --project_id=${GCP_PROJECT_ID} --format json < /tmp/daily-work.sql | jq '.[]')
SQL
次のようなSQLを実行して返ってきたJSONをよしなにしてSlackに毎日Slackへ通知して自分自身の進捗を把握するよう務めている
- daily-work.sql
#standardSQL # 固定値の算出 DECLARE day_of_sprint INT64; SET day_of_sprint = CASE EXTRACT(DAYOFWEEK FROM CURRENT_DATE()) WHEN 1 THEN 1 WHEN 2 THEN 2 WHEN 3 THEN 3 WHEN 4 THEN 4 WHEN 5 THEN 5 WHEN 6 THEN 1 WHEN 7 THEN 1 ELSE 1 END; # 作業データの分類 WITH work_view AS( ( SELECT CASE WHEN start > TIMESTAMP(CONCAT(DATE('${START_DATE}'), ' 17:00:00')) THEN 'recent0' WHEN start > TIMESTAMP(CONCAT(DATE('${START_DATE}')-7, ' 17:00:00')) THEN 'recent1' WHEN start > TIMESTAMP(CONCAT(DATE('${START_DATE}')-14, ' 17:00:00')) THEN 'recent2' WHEN start > TIMESTAMP(CONCAT(DATE('${START_DATE}')-21, ' 17:00:00')) THEN 'recent3' ELSE 'recent4' END as sprint, CASE WHEN description IN ('デイリースクラム', 'スプリントプランニング', 'スプリントレビュー', 'スプリントレトロスペクティブ') THEN 'scrum' WHEN description = 'レビュー' AND project = '会議' THEN 'review' ELSE 'dev' END as event_type, ROUND(SUM(dur)/60/60/1000,2) AS hours FROM `${GCP_PROJECT_ID}.toggl.times` WHERE workspace = 'work' AND 'ProjectA' IN UNNEST(tags) AND start > TIMESTAMP(CONCAT(DATE('${START_DATE}')-28, ' 17:00:00')) GROUP BY sprint, event_type ) UNION ALL ( SELECT CASE WHEN start > TIMESTAMP(CONCAT(DATE('${START_DATE}'), ' 17:00:00')) THEN 'recent0' WHEN start > TIMESTAMP(CONCAT(DATE('${START_DATE}')-7, ' 17:00:00')) THEN 'recent1' WHEN start > TIMESTAMP(CONCAT(DATE('${START_DATE}')-14, ' 17:00:00')) THEN 'recent2' WHEN start > TIMESTAMP(CONCAT(DATE('${START_DATE}')-21, ' 17:00:00')) THEN 'recent3' ELSE 'recent4' END as sprint, 'total' as event_type, ROUND(SUM(dur)/60/60/1000,2) AS hours FROM `${GCP_PROJECT_ID}.toggl.times` WHERE workspace = 'work' AND 'ProjectA' IN UNNEST(tags) AND start > TIMESTAMP(CONCAT(DATE('${START_DATE}')-28, ' 17:00:00')) GROUP BY sprint, event_type ) ), # 集計、過去との比較 compared_work_view AS ( SELECT sprint, event_type, hours, ROUND(hours/LEAD(hours, 1) OVER (PARTITION BY event_type ORDER BY sprint) * 100, 2) AS compared_1, ROUND(hours/LEAD(hours, 2) OVER (PARTITION BY event_type ORDER BY sprint) * 100, 2) AS compared_2, ROUND(hours/LEAD(hours, 3) OVER (PARTITION BY event_type ORDER BY sprint) * 100, 2) AS compared_3, ROUND(hours/LEAD(hours, 4) OVER (PARTITION BY event_type ORDER BY sprint) * 100, 2) AS compared_4, ROUND(hours/((LEAD(hours, 3) OVER (PARTITION BY event_type ORDER BY sprint) + LEAD(hours, 2) OVER (PARTITION BY event_type ORDER BY sprint) + LEAD(hours, 1) OVER (PARTITION BY event_type ORDER BY sprint)) / 3) * 100, 2) AS compared_recent3_avg, LEAD(hours, 1) OVER (PARTITION BY event_type ORDER BY sprint) AS lead1, LEAD(hours, 2) OVER (PARTITION BY event_type ORDER BY sprint) AS lead2, LEAD(hours, 3) OVER (PARTITION BY event_type ORDER BY sprint) AS lead3, LEAD(hours, 4) OVER (PARTITION BY event_type ORDER BY sprint) AS lead4 FROM work_view ORDER BY sprint ) # 直近スプリントのフィルタとフォーマット SELECT FORMAT("%s:%.2fh", event_type, hours) AS title, FORMAT("前S比: %.2f%s, 直近3S比: %.2f%s, 着地想定: %.2fh", IFNULL(compared_1, 0), '%', IFNULL(compared_recent3_avg, 0), '%', hours / day_of_sprint * 5) AS value FROM compared_work_view WHERE sprint = 'recent0'
以下で細かく分けて説明する
作業データの分類
- 集計対象としたいプロジェクト記録をタグで付けているのでタグで絞る
WHERE 'ProjectA' IN UNNEST(tags)
- 記録した日時によってどのスプリントでの記録か判断するためにCASE文で固定値を出力(sprint)
CASE WHEN start > TIMESTAMP(CONCAT(DATE('${START_DATE}'), ' 17:00:00')) THEN 'recent0' WHEN start > TIMESTAMP(CONCAT(DATE('${START_DATE}')-7, ' 17:00:00')) THEN 'recent1' WHEN start > TIMESTAMP(CONCAT(DATE('${START_DATE}')-14, ' 17:00:00')) THEN 'recent2' WHEN start > TIMESTAMP(CONCAT(DATE('${START_DATE}')-21, ' 17:00:00')) THEN 'recent3' ELSE 'recent4' END as sprint,
recent0は現スプリント、recent1が直前のスプリントとなる
- 作業内容によって大枠の作業分類を判定する(event_type)
CASE WHEN description IN ('デイリースクラム', 'スプリントプランニング', 'スプリントレビュー', 'スプリントレトロスペクティブ') THEN 'scrum' WHEN description = 'レビュー' AND project = '会議' THEN 'review' ELSE 'dev' END as event_type,
スクラムイベントとは別で作業時間としてこのくらい時間取りますという感じの取り決めを行っていたので作業分類を分けている
これはそもそもToggl側でしっかり分類できるように記録すれば良かったはなしだがそういう想定をしながら記録していなかったのでいい感じに行えずSQLで頑張ることになった
でこのあたりで合計値も出したくなったのでsprint,event_typeごとのSQLと、sprintごとのSQLをUNION ALLでつなげた
次のようにDATE_SUBなどを利用せず日付計算が行えるのは便利だと思った
DATE('${START_DATE}')-7
集計、過去との比較
SELECT sprint, event_type, hours, ROUND(hours/LEAD(hours, 1) OVER (PARTITION BY event_type ORDER BY sprint) * 100, 2) AS compared_1, ROUND(hours/LEAD(hours, 2) OVER (PARTITION BY event_type ORDER BY sprint) * 100, 2) AS compared_2, ROUND(hours/LEAD(hours, 3) OVER (PARTITION BY event_type ORDER BY sprint) * 100, 2) AS compared_3, ROUND(hours/LEAD(hours, 4) OVER (PARTITION BY event_type ORDER BY sprint) * 100, 2) AS compared_4, ROUND(hours/((LEAD(hours, 3) OVER (PARTITION BY event_type ORDER BY sprint) + LEAD(hours, 2) OVER (PARTITION BY event_type ORDER BY sprint) + LEAD(hours, 1) OVER (PARTITION BY event_type ORDER BY sprint)) / 3) * 100, 2) AS compared_recent3_avg, LEAD(hours, 1) OVER (PARTITION BY event_type ORDER BY sprint) AS lead1, LEAD(hours, 2) OVER (PARTITION BY event_type ORDER BY sprint) AS lead2, LEAD(hours, 3) OVER (PARTITION BY event_type ORDER BY sprint) AS lead3, LEAD(hours, 4) OVER (PARTITION BY event_type ORDER BY sprint) AS lead4 FROM work_view ORDER BY sprint
直近数スプリント分の作業時間とそれらを比較した現在進捗を出す
この時点ではウィンドウ関数を使って特定のレコードの前後の数値を持ってきて計算できるようにしている
前スプリントとの比率、直近3スプリントの平均値との比率を計算して出力させている
なので実際にほしいスコープ(本スプリント)の範囲より広めの期間で集計している
直前との比較がSQLで行えてしまうのすごい(小並感
直近スプリントのフィルタとフォーマット
最後の仕上げ
day_of_sprintの部分はスプリントが木曜締めなのでそれに合わせて今何日目なのかを固定値で出している
スクリプティングがSQLの中で普通に使えるのは使いやすい
余談だが実行にはbigquery.jobs.listの権限が追加で必要だった
DECLARE day_of_sprint INT64; SET day_of_sprint = CASE EXTRACT(DAYOFWEEK FROM CURRENT_DATE()) WHEN 1 THEN 1 WHEN 2 THEN 2 WHEN 3 THEN 3 WHEN 4 THEN 4 WHEN 5 THEN 5 WHEN 6 THEN 1 WHEN 7 THEN 1 ELSE 1 END; SELECT FORMAT("%s:%.2fh", event_type, hours) AS title, FORMAT("前S比: %.2f%s, 直近3S比: %.2f%s, 着地想定: %.2fh", IFNULL(compared_1, 0), '%', IFNULL(compared_recent3_avg, 0), '%', hours / day_of_sprint * 5) AS value FROM `${GCP_PROJECT_ID}.toggl.compared_work_view` WHERE sprint = 'recent0'
WHERE句で今スプリントでの数値を持ってくるようにする
WITH句でSQLを区切るとWHERE句で絞ってもウィンドウ関数で出した過去数値も参照できるよう
最初クエリ1つでHAVINGでいけるだろうとウィンドウ関数+HAVINGでやろうとしたができなかった
このことから処理順はSQLの実行結果にウィンドウ関数をよしなにやるという感じになっているのかなと感じた
着地想定はこの部分で計算している
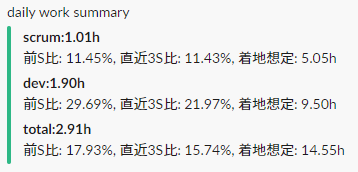
結果
こんな感じの出力になる
+-------------+---------------------------------------------------+ | title | value | +-------------+---------------------------------------------------+ | scrum:1.01h | 前S比: 11.45%, 直近3S比: 11.43%, 着地想定: 5.05h | | dev:1.90h | 前S比: 29.69%, 直近3S比: 21.97%, 着地想定: 9.50h | | total:2.91h | 前S比: 17.93%, 直近3S比: 15.74%, 着地想定: 14.55h | +-------------+---------------------------------------------------+
slackへの通知
クエリ部分以外の内容は本記事では省略しているがごにょごにょやって通知させた
よい
実行環境は何でも良いが現状はPrivateリポジトリでCIツールなどで実行して通知まで送っている
Slack通知まで含めるならGASが良さそうなのかな
CloudComposerを使うのも大げさそうだしかと言ってScheduledクエリでは完結できないのでどうするのがベターなのかなーと思っている
まとめ
- SQLクエリだけで集計やフォーマット、フィルタリングなど色々な作業が行えた
- かなり色々できるなーと感じた(SQLだけで頑張りたくなってくるw)
- クエリの勉強になった
- ウィンドウ関数
- 集計関数
- 日付計算
- WITH句
記事を書いていて、いまさらながらSTART_DATEの計算もQSLで行えそうな気がした
また、今回色々試した中でSQLだけでも実現できることがとても多く簡単な処理であればSQLだけで完結させたいと思いました
