 掲題の通りWorkflowsにBigQueryコネクタが来たので使ってみる
掲題の通りWorkflowsにBigQueryコネクタが来たので使ってみる
コネクタについてのドキュメントは下記
BigQuery API Connector Overview | ワークフロー | Google Cloud
要はWorkflowsから他のGoogleCloud製品にアクセスするための仕組み
今回はjobs.query,jobs.insertを使ってみる
googleapis.bigquery.v2.jobs.query
SQLクエリを実行して結果を取得するWorkflowを3つ書いてみた
10までのランダムな数値を返す
- connector-bigquery-query1.workflows.yml
- get_random: call: googleapis.bigquery.v2.jobs.query args: projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")} body: query: "SELECT CAST(FLOOR(10*RAND()) AS INT64)" useLegacySql: false result: query_result - log_result: call: sys.log args: text: ${query_result} severity: INFO - return_value: return: ${query_result}
- 結果
$ gcloud workflows deploy connector-bigquery-query --source=connector-bigquery-query1.workflows.yml
$ gcloud workflows run connector-bigquery-query
.....
.....
result: '{"cacheHit":false,"jobComplete":true,"jobReference":{"jobId":"job_iHlgd9bSdeQhZ8Yj_sTSuZxMNG2h","location":"US","projectId":"project-111111"},"kind":"bigquery#queryResponse","rows":[{"f":[{"v":"3"}]}],"schema":{"fields":[{"mode":"NULLABLE","name":"f0_","type":"INTEGER"}]},"totalBytesProcessed":"0","totalRows":"1"}'
state: SUCCEEDED
.....
.....
今回の実行結果は3
query_result.rows[0].f[0].vで取得できる
rows[0]の箇所が行数でf[0]の箇所が列数で割り当てられている
昨日の日付と一週間前の日付を返す
- connector-bigquery-query2.workflows.yml
- get_formatted_string: call: googleapis.bigquery.v2.jobs.query args: projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")} body: query: "SELECT FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)),FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 8 DAY))" useLegacySql: false result: query_result - log_result: call: sys.log args: text: ${query_result} severity: INFO - return_value: return: ${query_result}
- 実行結果
$ gcloud workflows deploy connector-bigquery-query --source=connector-bigquery-query2.workflows.yml
$ gcloud workflows run connector-bigquery-query
.....
.....
result: '{"cacheHit":false,"jobComplete":true,"jobReference":{"jobId":"job_e5kesd68UriZNQW5I35DZTw6dCMs","location":"US","projectId":"project-111111"},"kind":"bigquery#queryResponse","rows":[{"f":[{"v":"20210713"},{"v":"20210706"}]}],"schema":{"fields":[{"mode":"NULLABLE","name":"f0_","type":"STRING"},{"mode":"NULLABLE","name":"f1_","type":"STRING"}]},"totalBytesProcessed":"0","totalRows":"1"}'
startTime: '2021-07-14T03:29:53.535970733Z'
state: SUCCEEDED
.....
.....
対象を取得したい場合はquery_result.rows[0].f[0].v, query_result.rows[0].f[1].vなどでそれぞれ取得し他のステップで参照できる
今までだとWorkflowsで日付周りの処理やランダム数値などの値を取得するためには専用の関数を作って呼ぶ必要があった
正直そこまでするかーと思っている部分があったので上記のような手法でも代替が可能ではある
筋が良いかどうかは置いておいて…
バッチ用途での利用ならありかなーと思っている
リストを取得して処理を回す
blog_data.articlesテーブルに本ブログの記事データを保存しているのでこれを取ってきて逐次処理させるようなWorkflowを書いてみる
- connector-bigquery-query3.workflows.yml
- get_urls: call: googleapis.bigquery.v2.jobs.query args: projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")} body: query: "SELECT url FROM `blog_data.articles` WHERE updated > '2021-06-01'" useLegacySql: false result: target_urls - init: assign: - i: 0 - check_condition: switch: - condition: ${len(target_urls.rows) > i} next: iterate next: exit_loop - iterate: steps: - assign_value: assign: - target_url: ${target_urls.rows[i].f[0].v} - log: call: sys.log args: text: ${target_url} severity: INFO next: iterate-increment - iterate-increment: assign: - i: ${i+1} next: check_condition - exit_loop: return: 'done'
- 実行結果
$ gcloud workflows deploy connector-bigquery-query --source=connector-bigquery-query3.workflows.yml $ gcloud workflows run connector-bigquery-query ..... ..... result: '"done"' startTime: '2021-07-14T19:08:34.570860499Z' state: SUCCEEDED ..... .....
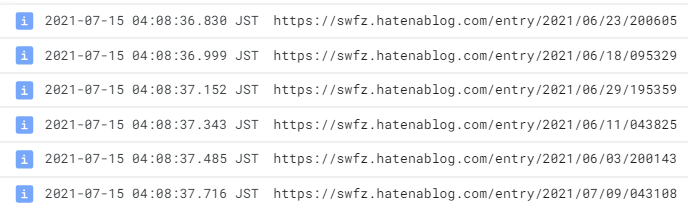
ログに出力されているのを確認
添字を用意してインクリメントして…みたいなことをせざるを得ないので微妙ではあるが回すことは可能
ただこれに関してはfor-inで配列走査できるようになるみたいなので期待して待っている(2021-07-10時点)
workflows-demos/workflow.yaml at master · GoogleCloudPlatform/workflows-demos
googleapis.bigquery.v2.jobs.insert
とりあえずGA4のデータからPV数を日別に集計して別テーブルに結果を入れ込む処理を書いた
- connector-bigquery-insert.workflows.yml
- init: assign: - project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")} - dataset_id: "sample_dataset" - table_id: "analytics_summary" - query: " SELECT DATE( timestamp_micros(event_timestamp), 'Asia/Tokyo' ) AS d, COUNT(1) AS pageview FROM `project-111111.analytics_1111111111.events_*`, UNNEST(event_params) AS params WHERE _TABLE_SUFFIX BETWEEN '20210601' and '20210630' AND event_name = 'page_view' AND params.key = 'page_location' GROUP BY d" - summary: call: googleapis.bigquery.v2.jobs.insert args: projectId: ${project_id} body: configuration: query: query: ${query} destinationTable: projectId: ${project_id} datasetId: ${dataset_id} tableId: ${table_id} create_disposition: "CREATE_IF_NEEDED" write_disposition: "WRITE_TRUNCATE" allowLargeResults: true useLegacySql: false jobReference: location: asia-northeast1 result: result - return: return: ${result}
- 実行
$ gcloud workflows deploy connector-bigquery-insert --source=connector-bigquery-insert.workflows.yml
$ gcloud workflows run connector-bigquery-insert
.....
.....
result: "{\"configuration\":{\"jobType\":\"QUERY\",\"query\":{\"allowLargeResults\"\
.....
.....
.....
0\",\"totalSlotMs\":\"2937\"},\"startTime\":\"1626203312130\",\"totalBytesProcessed\"\
:\"4149870\",\"totalSlotMs\":\"2937\"},\"status\":{\"state\":\"DONE\"},\"user_email\"\
.....
.....
.....
state: SUCCEEDED
.....
.....
上記レスポンス内容が結構な量だったので省略している
destinationTableへ集計結果が格納された
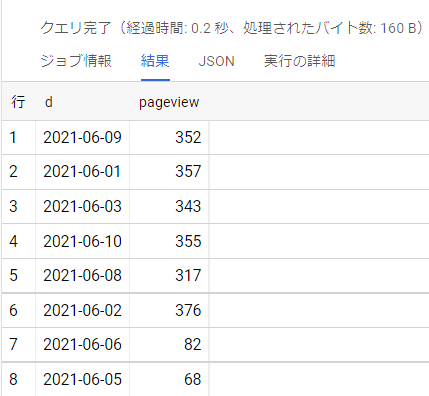
クエリパラメータを使う
パラメータ付きクエリも投げてみる
- connector-bigquery-insert.workflows.yml
- init: assign: - project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")} - dataset_id: "sample_dataset" - table_id: "analytics_summary" - query: " SELECT_ DATE( timestamp_micros(event_timestamp), 'Asia/Tokyo' ) AS d, COUNT(1) AS pageview FROM `project-111111.analytics_111111111.events_*`, UNNEST(event_params) AS params WHERE_ _TABLE_SUFFIX BETWEEN @start_date and @end_date AND event_name = 'page_view' AND params.key = 'page_location' GROUP BY d" - summary: call: googleapis.bigquery.v2.jobs.insert args: projectId: ${project_id} body: configuration: query: query: ${query} destinationTable: projectId: ${project_id} datasetId: ${dataset_id} tableId: ${table_id} create_disposition: "CREATE_IF_NEEDED" write_disposition: "WRITE_TRUNCATE" allowLargeResults: true useLegacySql: false queryParameters: - name: start_date parameterValue: value: "20210601" parameterType: type: STRING - name: end_date parameterValue: value: "20210610" parameterType: type: STRING jobReference: location: asia-northeast1 result: result - return: return: ${result}
コネクタで渡すパラメータの内容はコネクタのリファレンスからたどれば把握できるが結構ネストが深い
分かりづらかったので実際のAPIでたたく内容と照らし合わせて定義した
パラメータ付きのクエリに関しては次のドキュメントが参考になった
パラメータ化されたクエリの実行 | BigQuery | Google Cloud
所感
コネクタが使えるようになったのでWorkflowsでデータ整形のパイプラインを組むことが可能になった
が、Dataformとは違い依存関係を自動で整備して順序立てて実行してくれるわけではないので自分で組み立てる必要がある
また、最初クエリをyamlに直接書くのはどうなのかと思っていたけど書いてみたら別に…って感じだった
が、このへんはクエリの規模が大きくなったら感じ方変わりそう
できればSQLは別ファイルに切り出して管理したい感ある
実際に使っていく想定で考えると
ぱっと考えられそうなのは次の2案かなーと感じた
- 案1 SQLファイルはGCSへ置いて何かしらの方法で読み取ってBigQueryコネクタでSQLを実行する
ストレージのコネクタを使ってSQLはGCSへ置く、WorkflowsではGCSからSQLを読み取ってその内容をqueryに割り当てて実行するとういのを試みたが実力不足でコネクタだけでは実現できなかった
CloudFunctionを挟めばできるはずなのでサンプル実装を作ってみたい
- 案2 SQL実行用のWorkflowを用意し、メインのWorkflowで各種SQL用のWorkflowを制御する
Workflowから別Workflowを呼ぶことも可能なので1SQL:1WorkflowとかにしてSQLを書いたWorkflowをメインのWorkflowで制御するといった感じ
これならわりと管理しやすいかなーと感じた
どちらの案も環境ごとにプロジェクト、データセット、テーブルに用意したいみたいな話はSELECT時の対象テーブルをよしなにできる仕組みを実装しないと結局微妙な感じは否めないので「うーん…」となった
Dataformはその辺よしなに行えるのでやはり良いなーという感想です
