以前、Slack Workflow BuilderのWebhookを使って簡単記録用APIを作るという記事を書いた
他にも気軽に任意のデータを記録するためのアイデアを探していて、今回は掲題の内容で試してみた話
概要
直接APIの口を用意して…というわけではないがgcloudコマンドやPubSubのクライアントライブラリから直接データいれるというような使い方を想定
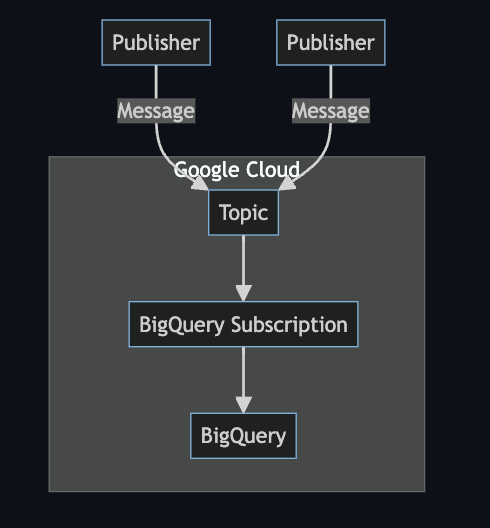
Publisherはどこの環境でも良いが今回はGitHubActionsからOIDCで連携できるようにしてgcloudコマンドでメッセージをpublishするようにしてみた
設定に必要な手間も少なくわりとサクッと実現まで行けたので想定通りでよかった
サブスクリプション
サブスクリプションの概要 | Pub/Sub ドキュメント | Google Cloud
トピックにパブリッシュされたメッセージを受信するには、そのトピックへのサブスクリプションを作成する必要があります。サブスクライバー クライアントで使用できるのは、サブスクリプションの作成後にトピックにパブリッシュしたメッセージだけです。サブスクライバー クライアントは、トピックにパブリッシュされたメッセージを受信して処理します。トピックは複数のサブスクリプションを持つことができますが、特定のサブスクリプションは単一のトピックに属します。
Pub/SubのBigQueryサブスクリプション
BigQuery サブスクリプション | Pub/Sub ドキュメント | Google Cloud
Pub/Subのサブスクリプションのひとつ
受信したメッセージの内容をあらかじめ設定してあるBigQueryのテーブルに記録する
BigQueryへの記録用にカスタムコードを書く必要がない
やってみる
連携先のBigQueryテーブルの用意
データセットはmetrics_lakeという名前であらかじめ作成しておく
- schema.json
[ { "name": "subscription_name", "type": "STRING", "mode": "NULLABLE", "description": "サブスクリプションの名前。" }, { "name": "message_id", "type": "STRING", "mode": "NULLABLE", "description": "メッセージのID。" }, { "name": "publish_time", "type": "TIMESTAMP", "mode": "NULLABLE", "description": "メッセージのパブリッシュ時刻。" }, { "name": "data", "type": "JSON", "mode": "NULLABLE", "description": "メッセージの本文。トピック スキーマを使用しない場合に必要です。" }, { "name": "attributes", "type": "JSON", "mode": "NULLABLE", "description": "すべてのメッセージ属性を含むJSONオブジェクト。Pub/Sub メッセージの一部である追加のフィールドも含まれます。" } ]
data列にメッセージが書き込まれる
bq mk --time_partitioning_field=publish_time --table metrics_lake.data schema.json
publish_timeがメッセージのmetadataから入ってくるのでそれを用いて対象データを刈り込みできるようにする
作成したmetrics_lake.dataというテーブルを後述のサブスクリプション作成で用いる
topic作成
メッセージの受け口となるTopicを作成する
$ gcloud pubsub topics create metrics Created topic [projects/project-111111/topics/metrics].
Subscription作成
Topicが受け取ったメッセージを処理するサブスクリプションを作成する
$ gcloud pubsub subscriptions create metrics-subscription \ --topic=projects/project-111111/topics/metrics \ --bigquery-table=project-111111:metrics_lake.data \ --drop-unknown-fields \ --write-metadata Created subscription [projects/project-111111/subscriptions/metrics-subscription].
--drop-unknown-fields
スキーマにないメッセージのフィールドが入っていた場合は通常エラーとなりBigQueryに記録されないがこのオプションで不明なフィールドを除外し記録できるようにしている
--write-metadata
Topicが受け取ったメッセージ自体の情報を記録するオプション、事前のテーブル作成で下記列を用意しておく必要がある
- subscription_name
- message_id
- publish_time
- data
- attributes
ドキュメントは下記
BigQuery サブスクリプションの作成 | Cloud Pub/Sub ドキュメント | Google Cloud
publish
publishして確認する
gcloud pubsub topics publish metrics --message='{"val": 3342, "key": "walk", "date":"2024-04-25"}'
JSONの中身は任意のデータ
bq queryで確認
bq query --use_legacy_sql=false --location asia-northeast1 'select * from metrics_lake.data'
+----------------------------------------------------------+-------------------+---------------------+-----------------------------------------------+------------+
| subscription_name | message_id | publish_time | data | attributes |
+----------------------------------------------------------+-------------------+---------------------+-----------------------------------------------+------------+
| projects/1111111111111/subscriptions/metrics-subscription | 11043552248007804 | 2024-04-25 10:37:44 | {"date":"2024-04-25","key":"walk","val":3342} | {} |
+----------------------------------------------------------+-------------------+---------------------+-----------------------------------------------+------------+
無事データが入ってきたことを確認できた
メッセージ内容はdata列に記録される
attributes
- Topicの属性(attribute)を指定してpublishすることもできる
- メッセージとは別なのでメッセージ内容とは別の要素を情報として付与したい場合などに使える
- 指定した属性はメタデータとして記録される
gcloud pubsub topics publish metrics --message='{"val": 2961, "key": "walk", "date":"2024-04-23"}' --attribute="source=pixela"
サンプルはこのデータがどこからのデータなのかを属性として渡している
--attribute="source=pixela"
余談だがPixelaのデータも他のデータと日別でJOINして色々やるときのために記録してみた
attributesにデータが入っているか確認
bq query --use_legacy_sql=false --location asia-northeast1 'select * from metrics_lake.data'
+----------------------------------------------------------+-------------------+---------------------+-----------------------------------------------+---------------------+
| subscription_name | message_id | publish_time | data | attributes |
+----------------------------------------------------------+-------------------+---------------------+-----------------------------------------------+---------------------+
| projects/1111111111111/subscriptions/metrics-subscription | 11043552248007804 | 2024-04-25 10:37:44 | {"date":"2024-04-25","key":"walk","val":3342} | {} |
| projects/1111111111111/subscriptions/metrics-subscription | 9544012833300734 | 2024-04-25 10:43:30 | {"date":"2024-04-23","key":"walk","val":2961} | {"source":"pixela"} |
+----------------------------------------------------------+-------------------+---------------------+-----------------------------------------------+---------------------+
GitHub ActionsからPublishする
OIDCでgcloudコマンドを実行できる前提で設定ファイルを記述しているが、OIDCの設定などは今回は割愛する
事前に下記作業を実施しておく
- サービスアカウントの作成
- サービスアカウントがOIDC経由で操作できるようWorkloadIdentityFederationの設定
Actionsの設定
WORKLOAD_IDENTITY_PROVIDER,OIDC_SERVICE_ACCOUNTは事前にGitHub側で設定を行っておく
name: metrics lake on: workflow_dispatch: jobs: publish-metrics: runs-on: ubuntu-latest permissions: contents: write id-token: write name: run script steps: - uses: actions/checkout@v4 with: fetch-depth: 200 # 直近3日なら200コミット以上しないだろうという想定のもとこの数値にしている - name: Authenticate on GCP id: auth uses: google-github-actions/auth@v2 with: create_credentials_file: true workload_identity_provider: ${{ vars.WORKLOAD_IDENTITY_PROVIDER }} service_account: ${{ vars.OIDC_SERVICE_ACCOUNT }} access_token_lifetime: 300s - name: Set up Cloud SDK uses: google-github-actions/setup-gcloud@v2 - name: publish run: | gcloud pubsub topics publish metrics --message='{"val": 50, "key": "score", "date":"2024-04-23"}' --attribute="source=obsidian"
最後のpublishのステップでパブリッシュしている
実際に使うならここで動的に値が出てくるようにスクリプト書いたりして任意のメッセージ内容になるようにコントロールする
おわり
PubSubのBigQuery Subscriptionを用いてPubSubからBigQueryへのデータ書き込みを行ってみた
この記事の内容になるまでいくつかのパターンで試してみたが、記事書きながらまとめてたら自分の中でも理解の怪しい部分が出てきたのでまた別途まとめられたらと思う
以下所感
- メリット
- システムからPub/Subにパブリッシュするだけでデータ記録できる
- 普通に便利
- ためたデータを時系列データって感じで扱える
- デッドレタートピックでよしなに処理してあげるようにすれば投げる側は楽かも
- 今回はそこまでやらなかった
- クライアント側でエラーハンドリングする必要がないのは一定楽だが、定義したスキーマに合わない場合や書き込みエラーになってしまう場合の考慮が必要
- システムからPub/Subにパブリッシュするだけでデータ記録できる
- 想定用途
- GitHub ActionsからCIの結果、テストのカバレッジやLinterの警告数など記録できそう
- こういうデータどうしようってのは割とある気がするので個人的にはこのユースケースが一番使えるかなという感じ
- システム横断で1つ用意してどんどんためていくとかそういう用途はイメージできる
- GitHub ActionsからCIの結果、テストのカバレッジやLinterの警告数など記録できそう
- 懸念
- 今回の手法だととりあえず一ヵ所にデータ集めてしまえるが、何でもかんでもになっていくとメンテナンスはきつくなりそう
- すぐ神テーブルになる可能性が…
- 設定で変更できる箇所が多いため設計次第
- 現時点で良さそう?な構成
- 記録するデータ種別毎にテーブル、Topic、Subscriptionを用意
- 要不要はテーブルを切り替えることで判断
- 全部一緒に扱いたくなったら後のELT工程でUNIONなりなんなりすればよい
- 記録するデータ種別毎にテーブル、Topic、Subscriptionを用意
- 現時点で良さそう?な構成
- 今回の手法だととりあえず一ヵ所にデータ集めてしまえるが、何でもかんでもになっていくとメンテナンスはきつくなりそう
