プライベートでブログのPVなどを集計していて
BigQueryにTwitterのエゴサやGoogleAnalyticsのPVなどを取り込んで、Dataportalから参照してグラフにして定期的に見るようにしている
記事についてのデータ(urlやタグ)はjsonで持っていてこちらもBigQueryに定期的に同期してそれを用いてこの記事がいつ書かれてPVはこんな感じ
といったようなことをさっと把握できるようにしていた
記事ごとに集計していたがせっかく「タグ」の情報も持っているのでタグごとにも集計結果を見れるようインタラクティブフィルタをうまく使いたいと思っていた
色々調べてみるとどうやらDataportalのフィルタの制約をクリアすれば実現できそうということでやってみた
イメージ

インタラクティブフィルタについて
インタラクティブフィルタは基本的には同じデータソース間で適用される
しかし次のドキュメントを読むと
データソース間でコントロールを使用する - データポータルのヘルプ
フィルタ処理は、データソース内に表示されているフィールド名ではなく、内部的なフィールド ID をもとに行われているためです
ということで、適当に名前を合わせたフィールドを作成してもフィルタは適用されない
が、内部的なフィールドIDが同じであればデータソースが異なっていてもインタラクティブフィルタが適用できる
共通するフィールドIDをarticle.idにして各種数値データはarticleとレポートデータを混合データにして扱うことで同じIDを扱えるようになり、異なるデータソース間でもインタラクティブフィルタを適用できるはず
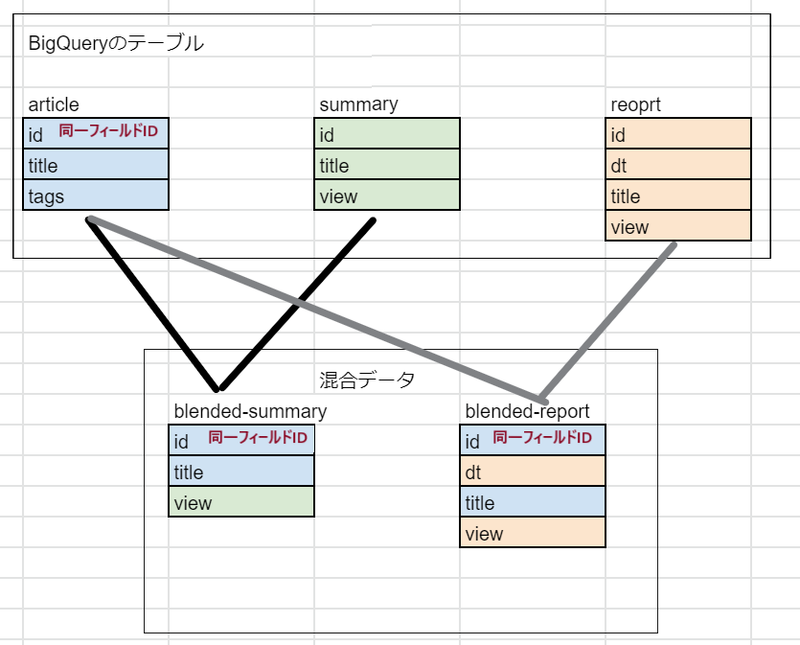
ということで実践してみる
サンプルデータ投入
- sample-report.json
{"dt":"2021-06-15","id":1,"title":"hoge","view":1} {"dt":"2021-06-15","id":2,"title":"fuga","view":1} {"dt":"2021-06-15","id":3,"title":"piyo","view":1} {"dt":"2021-06-15","id":4,"title":"foo","view":1} {"dt":"2021-06-15","id":5,"title":"bar","view":1} {"dt":"2021-06-16","id":1,"title":"hoge","view":2} {"dt":"2021-06-16","id":2,"title":"fuga","view":1} {"dt":"2021-06-16","id":3,"title":"piyo","view":1} {"dt":"2021-06-16","id":4,"title":"foo","view":1} {"dt":"2021-06-16","id":5,"title":"bar","view":1} {"dt":"2021-06-17","id":1,"title":"hoge","view":2} {"dt":"2021-06-17","id":2,"title":"fuga","view":1} {"dt":"2021-06-17","id":3,"title":"piyo","view":2} {"dt":"2021-06-17","id":4,"title":"foo","view":1} {"dt":"2021-06-17","id":5,"title":"bar","view":3}
- sample-summary.json
{"id":1,"title":"hoge","view":5} {"id":2,"title":"fuga","view":3} {"id":3,"title":"piyo","view":4} {"id":4,"title":"foo","view":3} {"id":5,"title":"bar","view":5}
- article.json
{"id":1, "title": "hoge", "tags": ["A","B"]} {"id":2, "title": "fuga", "tags": ["C","D"]} {"id":3, "title": "piyo", "tags": ["A"]} {"id":4, "title": "foo", "tags": ["C"]} {"id":5, "title": "bar", "tags": ["E"]}
- 投入
bq load --autodetect --replace --source_format=NEWLINE_DELIMITED_JSON sample.report sample-report.json bq load --autodetect --replace --source_format=NEWLINE_DELIMITED_JSON sample.summary sample-summary.json bq load --autodetect --replace --source_format=NEWLINE_DELIMITED_JSON sample.article article.json
- スキーマの確認
$ bq show --schema --format=json sample.article
[{"name":"tags","type":"STRING","mode":"REPEATED"},{"name":"title","type":"STRING","mode":"NULLABLE"},{"name":"id","type":"INTEGER","mode":"NULLABLE"}]
$ bq show --schema --format=json sample.summary
[{"name":"view","type":"INTEGER","mode":"NULLABLE"},{"name":"title","type":"STRING","mode":"NULLABLE"},{"name":"id","type":"INTEGER","mode":"NULLABLE"}]
$ bq show --schema --format=json sample.report
[{"name":"view","type":"INTEGER","mode":"NULLABLE"},{"name":"id","type":"INTEGER","mode":"NULLABLE"},{"name":"title","type":"STRING","mode":"NULLABLE"},{"name":"dt","type":"DATE","mode":"NULLABLE","description":"%E4Y-%m-%d"}]
それぞれidをもとにひも付けていく前提の中身となっている
データソースの追加
- BigQueryのデータソースを指定する
普通に追加するだけ
articleについて
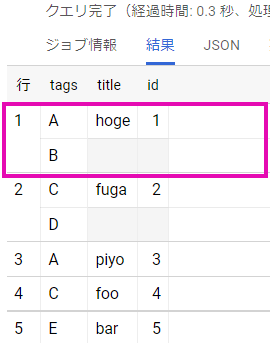
article.tagsはstringの配列だがDataportal上で表を追加するとBigQueryでUNNESTを使用してクエリしたときと同じような表示のされ方をする
- BigQueryでSELECT
- Dataportalで表を追加
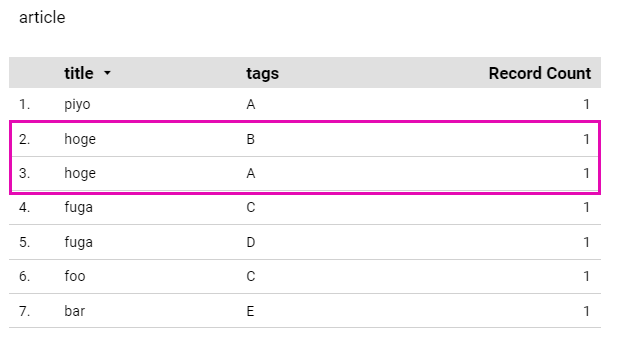
BigQueryのレコード上では id:1のhogeは1レコードだが図のようにtitle: hoge, tags: Aとtitle: hoge, tags: Bと2レコードあるように見える
そういうの解釈してくれるのか!すごい!
と思ったが、無邪気に配列カラムのあるデータをDataportalで表示したらなんか計算があわないぞ?といったことになりかねないのでこの挙動は覚えておく必要がありそう
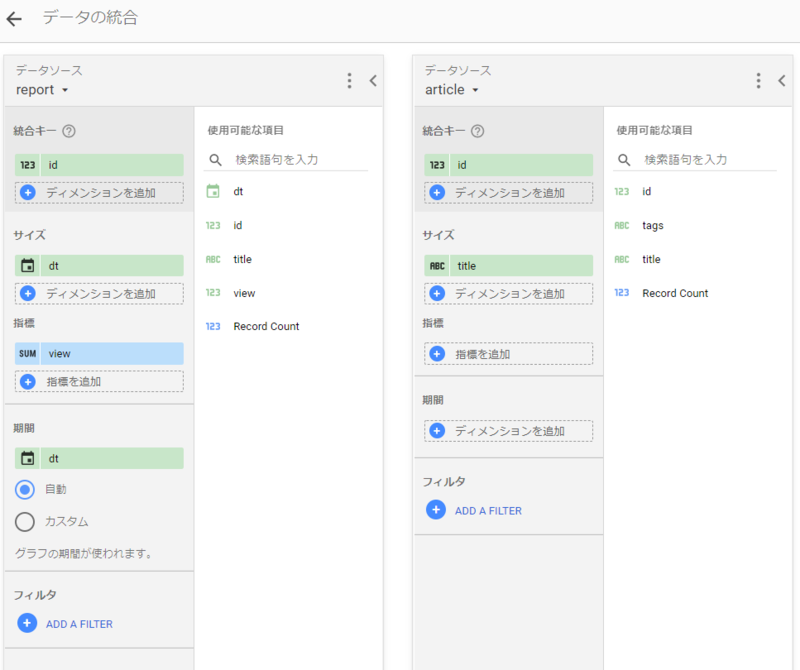
混合データを作成
ベース側はレポート、IDをキーとして結合する
- blended-report
- blended-summary
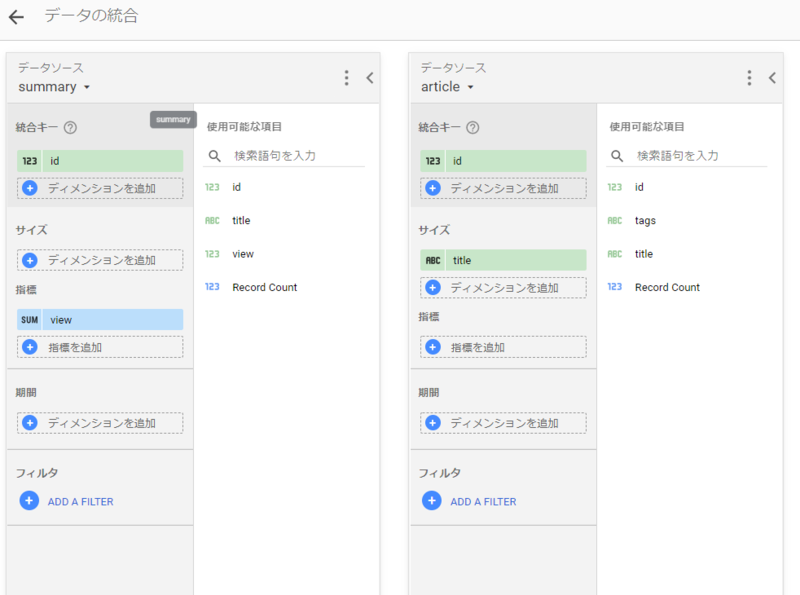
サイズにtagsを含めないのがポイントのよう
グラフを追加
タグの割合
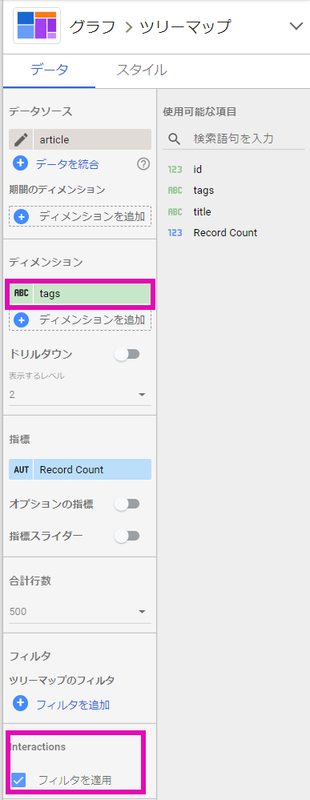
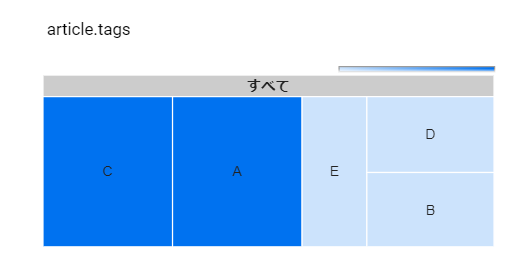
ツリーマップを使ってみる
article tagsを入れる、インタラクティブフィルタを有効にする
レポートデータ
reportのみ抜粋してスクショしておく
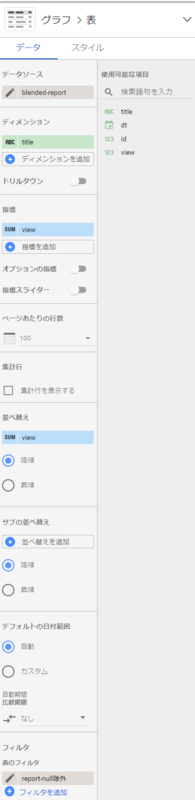
フィルタを作成
reportのみ抜粋してスクショしておく
summaryも同様に設定することで同じ挙動にできる
グラフの設定からフィルタを追加する(title nullを除外する)
このフィルタがないと対象カテゴリ以外のデータがtitle=nullで計算されてしまう
- blended-report

- フィルタがない場合の挙動
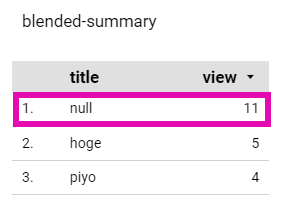
表示
準備ができたのでいじってみる
結合用のキーid を用いている他の混合データもフィルタリングされる
挙動的には再度クエリ投げているように見える

1.で選択されたtagsがあるレコードのIDにひも付いているレコードのみ各表のtitleが表示される、ひも付かないレコードのtitleはnull(9.の表で確認できる)
グラフのフィルタによりtitle=nullのレコードを除外することでフィルタリングできたように見せることが可能になる(5.)
これでOK!と思っていたが色々触ってたらまた疑問が出てきた
articleのデータを表示した表(2.,.3)の間で、tagsを含む表と含まない表でインタラクティブフィルタの挙動が変わる
tagsなしの表(3.)では他の統合データと粒度が合うのでグラフのフィルタがなくても絞り込みができる
(3.のフィルタを適用させて9.をみるとtitle=nullの行が存在しない)
tagsなしの表(3.)でインタラクティブフィルタを使うと無関係だと思っていた7.の表もフィルタリングされた…自分としては想定外だったのでどのような理屈でこうなっているのか正直イメージがついていない…
なにはともあれ無事tagsで他グラフのデータをフィルタリングができるようになった
まとめ
- Dataportalのインタラクティブフィルタを活用した
- 混合データを駆使して出どころの違うデータソースでもインタラクティブフィルタを適用できた
- DataportalがBigQueryの配列カラムをよしなに解釈してくれることがわかった
- ベースは記事ごとだが、より細かい粒度の単位でも集計したいみたいなパターンでこの方法を使えそう
他にもジャンルなどを追加してみて傾向を分析したりしてみたい
