2020年からじぶんリリースノート(毎月の振り返り的な記事)を書いていた
ここ1年くらいは書く項目が「仕事」「生活」など固定化されてきていたためこれらの文章を使って感情分析にかけたら年間を通してどんな感情だったのかというのが定量的に測れそう
ということでさっそくやってみた
まずNatural Lauguage APIを試してみる
感情分析 | Cloud Natural Language API | Google Cloud
quickstartが用意されているのでよくありそうな文言を記入してとりあえず試してみる
なんとなくnodeでやってみた(参考リンクのコードそのままコピーしたら動かなかったのでこちらにも載せておく)
// Imports the Google Cloud client library const language = require('@google-cloud/language'); // Creates a client const client = new language.LanguageServiceClient(); /** * TODO(developer): Uncomment the following line to run this code. */ const text = `今日はいろいろうまく行かないことが重なってしまいました。 明日は頑張ってミスしないように気をつけたいと思います。 `; // Prepares a document, representing the provided text const document = { content: text, type: 'PLAIN_TEXT', }; async function analyze() { // Detects the sentiment of the document const [result] = await client.analyzeSentiment({document}); const sentiment = result.documentSentiment; console.log('Document sentiment:'); console.log(` Score: ${sentiment.score}`); console.log(` Magnitude: ${sentiment.magnitude}`); const sentences = result.sentences; sentences.forEach(sentence => { console.log(`Sentence: ${sentence.text.content}`); console.log(` Score: ${sentence.sentiment.score}`); console.log(` Magnitude: ${sentence.sentiment.magnitude}`); }); } analyze();
- 結果
Document sentiment: Score: -0.4000000059604645 Magnitude: 0.8999999761581421 Sentence: 今日はいろいろうまく行かないことが重なってしまいました。 Score: -0.800000011920929 Magnitude: 0.800000011920929 Sentence: 明日は頑張ってミスしないように気をつけたいと思います。 Score: -0.10000000149011612 Magnitude: 0.10000000149011612
ネガティブな感じになっている
release noteの一部文章を抜き出してNaturalLanguageAPIに投げてみる
ここから実際のテキストを抜き出して使ってみる
流れ
- release noteの定形な部分の文章を取り出す
arkdown-to-astを使ってASTを取得- 特定見出しの文章の範囲を取得
- たとえば(Headerで「仕事」)の記述があるブロックなど
- 取り出した文章をNatural Lauguage APIの感情分析にかけ、結果をCSVに出力する
- 結果のCSVをデータポータルにアップロードし、月ごとの感情変化をグラフにする
release noteの定形な部分の文章を取り出す
@textlint/markdown-to-ast - npm
MarkdownでAST扱うならということで思い浮かんだのがtextlintだったのでそこから探していったが、markdown-to-ast自体はASTの生成を行っているわけではないようなので内部的に使っているremarkjs/remarkを直接使ったほうが良かったかもしれない
気付いたのが記事書いている最中だったのでこのまま進める
例として下記のようなmakrdownファイルを解析対象とする場合
- /path/to/file.md(一部抜粋)
## 仕事 こんな事がありました ## 生活 ○○を買いました ## 趣味 こんなことをしました
const parse = require("@textlint/markdown-to-ast").parse; const mdFile = '/path/to/file.md'; const targetTitle = '生活'; const markdown = fs.readFileSync(mdFile, 'utf8').toString(); const AST = parse(markdown); const headerIndexes = AST.children.flatMap((item,i) => (item.type === 'Header' && item.raw.match(/#/g).length === 2) ? {i: i, raw: item.raw} : []); const tmpIndex = headerIndexes.findIndex(item => item.raw.match(targetTitle)); const targetIndexes = headerIndexes.slice(tmpIndex, tmpIndex + 2).map(item => item.i); const targetTree = AST.children.slice(...targetIndexes); const targetText = targetTree.filter(item => item.type === 'Paragraph').map(item => item.raw).join("\n"); console.log(targetText);
やっていることは
targetTitleが含まれる## 生活のようなh2のHeaderから次のh2のHeaderまでの項(Paragraph)のテキストをつなげて抽出する
今回は文中にリストやh3などのHeaderがあった場合は抽出対象に含めていない
もっとうまい方法はありそうだが結果を出せて満足してしまった…
取り出した文章をNatural Lauguage APIの感情分析にかける
いきなりコードをドン!になってしまったが次のようなコードを書いて複数ファイル、複数項目記入して分析対象とする感じにした
const fs = require('fs'); const createCsvWriter = require('csv-writer').createObjectCsvWriter; const parse = require("@textlint/markdown-to-ast").parse; const language = require('@google-cloud/language'); // 計測対象のファイルを列挙する const files = [ { month: '2021-01', file: 'samples/sample1.md' }, { month: '2021-02', file: 'samples/sample2.md' }, ]; // 計測対象の文言を記述する(`## `で始まる段落) const titles = ['仕事', '生活']; const extractText = (mdFile, targetTitle) => { console.log(mdFile); const markdown = fs.readFileSync(mdFile, 'utf8').toString(); const AST = parse(markdown); const headerIndexes = AST.children.flatMap((item,i) => (item.type === 'Header' && item.raw.match(/#/g).length === 2) ? {i: i, raw: item.raw} : []); const tmpIndex = headerIndexes.findIndex(item => item.raw.match(targetTitle)); const targetIndexes = headerIndexes.slice(tmpIndex, tmpIndex + 2).map(item => item.i); const targetTree = AST.children.slice(...targetIndexes); const targetText = targetTree.filter(item => item.type === 'Paragraph').map(item => item.raw).join("\n"); return targetText; } async function analyze(file, targetTitle) { // Instantiates a client const client = new language.LanguageServiceClient(); const text = extractText(file, targetTitle); const document = { content: text, language: 'ja', type: 'PLAIN_TEXT', }; // Detects the sentiment of the text const [result] = await client.analyzeSentiment({document: document}); const sentiment = result.documentSentiment; console.log(sentiment); console.log(`Text: ${text}`); console.log(`Sentiment score: ${sentiment.score}`); console.log(`Sentiment magnitude: ${sentiment.magnitude}`); return {...sentiment, length: text.length}; } async function main() { const data = []; for (title of titles) { for (line of files) { const result = await analyze(line.file, title); data.push({month: line.month, type: title, score: result.score, magnitude: result.magnitude, length: result.length}); } } const csvWriter = createCsvWriter({path: 'result.csv', header: ['month', 'type', 'score', 'magnitude', 'length']}); await csvWriter.writeRecords(data).then(() => {}); } main()
CSVをローカルへ書き込むようにしたのはデータポータルのアップロードに対応しているのがCSVのため
直接BigQueryに突っ込んでしまっても良いかもしれない
上記スクリプトは冒頭のやりたいことに合わせてfilesに月の要素を含めてしまった
もし流用するならよしなに変えてもらえればと思う
実行結果を見てみる
- result.csv
2021-01,仕事,-0.800000011920929,0.800000011920929 2021-02,仕事,0.8999999761581421,2.700000047683716 2021-01,生活,0.4000000059604645,2.200000047683716 2021-02,生活,0,1.5
月ごとの感情変化をグラフにする
今回は単発で可視化するだけだったのでCSVに書き出してDataPortalにアップロードして可視化した
実際のリリースノート2021年分から取得してきた結果は下記
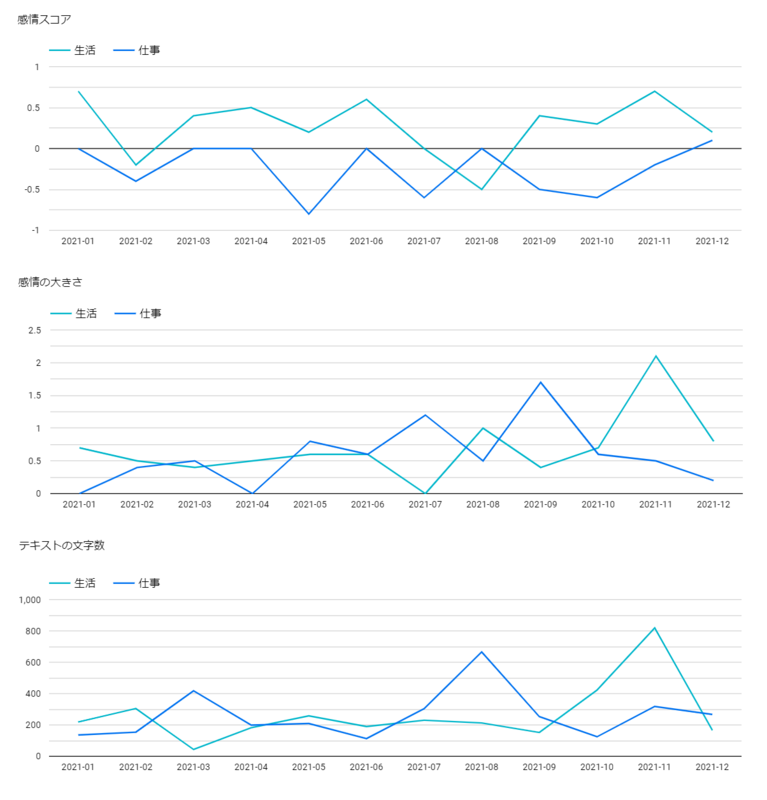
仕事、生活がある程度連動してそうってことが読み取れた
感情の大きさに関しては文字数の量にも関連があるとドキュメントにも載っていた覚えがあるが本当そう
まとめ
- Natural Language APIを使って文章の感情分析を行った
- リリースノートの各月の特定の章の文章を抜き出した
- 月ごとの感情変化を読み取ることができた
この数値をどのくらい信用して良いかみたいなところはありそうだけど傾向を探る分には十分かなと感じた
振り返りとかの文章だと結構感情がでやすいかも?
現在Notionで日次/週次/月次の振り返りも書いているのでそのあたりも分析にかけてみると面白いかも
日次の結果を月末振り返る際に感情分析して「このときこうだったなー」と思い出しながら振り返ってみるのも良さそう
貯まってきたらやってみたい
今回使ったコードなどは下記リポジトリに置いた
swfz/markdown-sentence-sentiment: Measure emotions from specific chapter sentences in markdown.
