取り込み時間パーティションと日付 / タイムスタンプ パーティションの違いについて
しっかりしたドキュメントがあるのでそっち読むほうが断然良いと思います
実際に触ってみたら分かるがドキュメント読むだけだといまいちピンと来なかったので触りながら把握したときのメモ
取り込み時間パーティション
取り込み時間パーティション分割テーブルの作成と使用 | BigQuery | Google Cloud
雑な言い方をすればスキーマで定義するカラムの中にパーティションフィールドがない
逆に言うと日付などの情報をカラムに含めなくて良い
日付 / タイムスタンプ パーティション
日付 / タイムスタンプ パーティション分割テーブルの作成と使用 | BigQuery | Google Cloud
日付や時刻のカラムをパーティション対象として指定する
それぞれ操作してみる
CLI経由で操作
取り込み時間パーティション
- テーブルの作成
$ bq mk -t \ --schema 'dt:DATE,column1:STRING,column2:INTEGER' \ --time_partitioning_type DAY \ --require_partition_filter \ --description "This is my partitioned table" \ --label org:dev \ sample.pt_sample2
- 確認
$ bq show --format=prettyjson demo-000000:sample.pt_sample2
- 結果
{ "creationTime": "1600937209910", "description": "This is my partitioned table", "etag": "m4EdQtu0abp7cN/Ph3iSKQ==", "id": "demo-000000:sample.pt_sample2", "kind": "bigquery#table", "labels": { "org": "dev" }, "lastModifiedTime": "1600937209948", "location": "US", "numBytes": "0", "numLongTermBytes": "0", "numRows": "0", "requirePartitionFilter": true, "schema": { "fields": [ { "name": "dt", "type": "DATE" }, { "name": "column1", "type": "STRING" }, { "name": "column2", "type": "INTEGER" } ] }, "selfLink": "https://bigquery.googleapis.com/bigquery/v2/projects/demo-000000/datasets/sample/tables/pt_sample2", "tableReference": { "datasetId": "sample", "projectId": "demo-000000", "tableId": "pt_sample2" }, "timePartitioning": { "requirePartitionFilter": true, "type": "DAY" }, "type": "TABLE" }
適当にデータを用意してデータを入れてみる
$ cat 0921.jsonl.json
{"dt":"2020-09-21","column1":"hoge","column2":5}
{"dt":"2020-09-21","column1":"fuga","column2":3}
$ cat 0920.jsonl.json
{"dt":"2020-09-20","column1":"hoge","column2":1}
{"dt":"2020-09-20","column1":"fuga","column2":2}
$ bq load \ --replace \ --source_format=NEWLINE_DELIMITED_JSON \ 'sample.pt_sample2$20200921' \ ./0921.jsonl.json $ bq load \ --replace \ --source_format=NEWLINE_DELIMITED_JSON \ 'sample.pt_sample2$20200920' \ ./0920.jsonl.json
time_partitioning_typeは必要
これがないとパーティション分割テーブルという情報がないため普通のテーブルと認識されてしまう
そのため後のデータ入れ込み時にパーティションデコレータなどでパーティションを指定してもエラーでロードできない
日付 / タイムスタンプ パーティション
- テーブルの作成
$ bq mk -t \ --schema 'dt:DATE,column1:STRING,column2:INTEGER' \ --time_partitioning_field dt \ --time_partitioning_type DAY \ --require_partition_filter \ --description "This is my partitioned table" \ --label org:dev \ sample.pt_sample
- 確認
$ bq show --format=prettyjson demo-000000:sample.pt_sample
- 結果
{ "creationTime": "1600750344111", "description": "This is my partitioned table", "etag": "s9//dF45CxqBBzOTpCI50A==", "id": "demo-000000:sample.pt_sample", "kind": "bigquery#table", "labels": { "org": "dev" }, "lastModifiedTime": "1600750612630", "location": "US", "numBytes": "88", "numLongTermBytes": "0", "numRows": "4", "requirePartitionFilter": true, "schema": { "fields": [ { "name": "dt", "type": "DATE" }, { "name": "column1", "type": "STRING" }, { "name": "column2", "type": "INTEGER" } ] }, "selfLink": "https://bigquery.googleapis.com/bigquery/v2/projects/demo-000000/datasets/sample/tables/pt_sample", "tableReference": { "datasetId": "sample", "projectId": "demo-000000", "tableId": "pt_sample" }, "timePartitioning": { "field": "dt", "requirePartitionFilter": true, "type": "DAY" }, "type": "TABLE" }
こちらはパーティションフィールドが設定されている
違いはtimePartitioning.fieldがあるかどうかくらい
適当にデータを用意してデータを入れてみる
$ cat 0921.jsonl.json
{"dt":"2020-09-21","column1":"hoge","column2":5}
{"dt":"2020-09-21","column1":"fuga","column2":3}
$ cat 0920.jsonl.json
{"dt":"2020-09-20","column1":"hoge","column2":1}
{"dt":"2020-09-20","column1":"fuga","column2":2}
$ bq load \ --replace \ --source_format=NEWLINE_DELIMITED_JSON \ 'sample.pt_sample$20200921' \ ./0921.jsonl.json $ bq load \ --replace \ --source_format=NEWLINE_DELIMITED_JSON \ 'sample.pt_sample$20200920' \ ./0920.jsonl.json
Embulkで操作
$ embulk --version embulk 0.9.23
取り込み時間パーティション
- 設定ファイル(out部分のみ抜粋)
out: type: bigquery project: {{ env.PROJECT_ID }} mode: replace dataset: blog_data table: ga_events$20200801 location: asia-northeast1 compression: GZIP auto_create_table: true source_format: NEWLINE_DELIMITED_JSON auth_method: service_account json_keyfile: {{ env.GOOGLE_APPLICATION_CREDENTIALS }}
試行錯誤した結果この設定方法になった
パーティションデコレータをテーブル名へ追加することでEmbulk側がよしなにしてくれる
日付 / タイムスタンプ パーティション
- 設定ファイル(out部分のみ抜粋)
out: type: bigquery project: {{ env.PROJECT_ID }} mode: replace dataset: blog_data table: ga_events$20200801 location: asia-northeast1 compression: GZIP auto_create_table: true source_format: NEWLINE_DELIMITED_JSON auth_method: service_account json_keyfile: {{ env.GOOGLE_APPLICATION_CREDENTIALS }} time_partitioning: type: DAY field: date
time_partitioningの設定を入れる- スキーマ中の何かしらの列をパーティションカラムに設定する必要がある
- 日付/タイムスタンプパーティショニング
- スキーマ中の何かしらの列をパーティションカラムに設定する必要がある
select
取り込み時間パーティション
_PARTITIONTIME,_PARTITIONDATEなどの疑似列が存在する
require_partition_filterが設定されていると次のように擬似列をWHERE句に含めないとエラーになる
$ bq query --use_legacy_sql=false 'select * from sample.pt_sample2' Error in query string: Error processing job 'demo-000000:bqjob_r697941c074af8399_00000174bf507888_1': Cannot query over table 'sample.pt_sample2' without a filter over column(s) '_PARTITION_LOAD_TIME', '_PARTITIONDATE', '_PARTITIONTIME' that can be used for partition elimination
パーティションタイプをDAY にしている場合しか確認してないが_PARTITION_LOAD_TIME, _PARTITIONDATE, _PARTITIONTIMEどれを指定してもクエリできた
$ bq query --use_legacy_sql=false 'select * from sample.pt_sample2 where _PARTITIONDATE="2020-09-21"' +------------+---------+---------+ | dt | column1 | column2 | +------------+---------+---------+ | 2020-09-21 | hoge | 5 | | 2020-09-21 | fuga | 3 | +------------+---------+---------+
日付 / タイムスタンプ パーティション
こちらは疑似列が存在しないので疑似列を含めてクエリすると怒られる
$ bq query --use_legacy_sql=false 'select * from sample.pt_sample where _PARTITIONDATE="2020-09-21"' Error in query string: Error processing job 'demo-000000:bqjob_r52e132d14c4058e7_00000174bf4ddd41_1': Unrecognized name: _PARTITIONDATE at [1:38]
- パーティションカラムを指定してクエリ
$ bq query --use_legacy_sql=false 'select * from sample.pt_sample where dt="2020-09-21"' +------------+---------+---------+ | dt | column1 | column2 | +------------+---------+---------+ | 2020-09-21 | hoge | 5 | | 2020-09-21 | fuga | 3 | +------------+---------+---------+
DataPortalからの利用
データソースを選択するとき
require_partition_filterが設定されている場合は選択権がない
取り込み時間パーティション
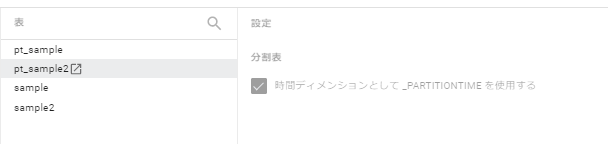
日付 / タイムスタンプ パーティション
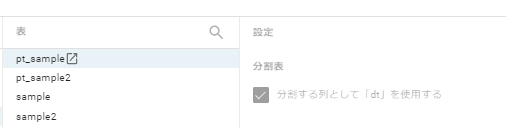
まとめ
- テーブル作成時にパーティションカラムを指定するかしないかでタイプが変わる
- Embulkのプラグインは渡すオプションによってよしなにやってくれていたのであまり意識することがなかっただけ
取り込み時間パーティション
- カラムの中に日付などの情報を持たせなくても良い
- 疑似列を用いて対象パーティションを絞り込む
日付 / タイムスタンプ パーティション
- 明示的に指定したカラムを用いて対象パーティションを絞り込む
まぁ終わってみれば「そうだよね」という感じになりましたw
基本的に日付/タイムスタンプパーティションを使うが
日付などの情報をもたせる必要がない場合、履歴含め取り込む時期に意味をもたせたい場合、1次データの置き場として取り込み時間でパーティションする
みたいな使い分けかなと感じました
