ここ数ヵ月Togglを用いて仕事、プライベートの勉強時間、睡眠時間のトラッキングを続けています
Togglにもレポートはあるのですが無料プランだと次の点で不満がありました
- workspaceをまたいだデータが閲覧できない
- projectごとのデータをレポート画面で見ることができない
- 一応期間1日指定であれば割合は把握できるけど…

ということで前々から使ってみたかったBigQueryとDataPortalを使って上記を踏まえてレポートデータを可視化してみました
結果はこのような感じ

仕事の時間もある程度とっていてそちらでタグは使用しています
プライベートでは使い方を決めきれていないのでまだ何も設定していません
可視化までの流れ
大まかなながれは次のようになります
- Toggl APIを使い詳細データを取得しファイルに保存
- 保存したデータをGCSへアップロード
- アップロードしたGCSからBigQueryにデータをロード
- DataPortalでBigQueryコネクターを使用してダッシュボードを作成
そんなにステップ多くないですね
Toggl API
APIはToggl APIとReports APIの2つがあり今回はReports APIを使用します
API KeyはProfile settingsの下の方に記述されているキーを使用します
- document
toggl/toggl_api_docs: Documentation for the Toggl API
toggl_api_docs/reports.md at master · toggl/toggl_api_docs
4つエンドポイントが用意されているのでとりあえず試してみて一番詳細にデータが取れそうなDetailed reportのエンドポイントを使ってデータを取得するようにしました
パラメータ
次のパラメータは必須
- user_agent
- workspace_id
今回は必須のほかに次のパラメータも追加してリクエストするようにしました
- page
- since
- until
TogglのAPIではレスポンスできる件数に制限があり一度に50件ほどまでしか取得できません
detailedエンドポイントに関してはpageパラメータが用意されていてページングでのリクエストが送れます
一度に全workspaceの全データを取得するにはpageパラメータを増やしながら複数リクエストを送る必要があるので雑ですがスクリプトを書いてます
TOGGL_API_TOKENを読み込ませておきスクリプトを実行します
- request.sh
#!/bin/bash
workspace_id=$1
workspace_name=$2
start_date=$3
end_date=$4
month=$5
request() {
page=$1
res=`curl -u ${TOGGL_API_TOKEN}:api_token -XGET "https://api.track.toggl.com/reports/api/v2/details?page=${page}&workspace_id=${workspace_id}&since=${start_date}&until=${end_date}&user_agent=api_test"`
echo ${res} | jq -cr '.data|.[]|.start=(.start|gsub("T";" ")|gsub("\\+09:00$";""))|.end=(.end|gsub("T"; " ")|gsub("\\+09:00$";""))|.updated=(.updated|gsub("T"; " ")|gsub("\\+09:00$";""))|.start_date=(.start|gsub(" .*"; ""))' >> ${workspace_name}/${month}.json
total=`echo ${res} | jq -cr '.total_count'`
per_page=`echo ${res} | jq -cr '.per_page'`
length=`echo ${res} | jq -cr '.data|length'`
cursor=$(((page-1) * per_page + length))
if [ ${cursor} -lt ${total} ]; then
request $((page + 1))
fi
}
request 1
jqでゴニョゴニョやっている箇所はスキーマ自動検出時にTIMESTAMPで保存できるように少し整えています
私の場合仕事、勉強、睡眠とそれぞれ違うworkspaceで記録しているのでworkspaceごとにスクリプトをたたいてファイルへ保存するようにしています
sh ./request.sh {仕事のworkspace_id} work 2020-05-01 2020-05-29 2020-05-01
sh ./request.sh {勉強のworkspace_id} private 2020-05-01 2020-05-29 2020-05-01
sh ./request.sh {睡眠のworkspace_id} default 2020-05-01 2020-05-29 2020-05-01
GCSへのアップロード
あらかじめ適当なバケットを作成しておきgsutilコマンドをたたくだけです
gsutil cp work/2020-05-01.json gs://swfz-timetracker/toggl/month=2020-05-01/workspace=work/report.json
- GCSのディレクトリ構成
列挙すると次のような配置になっています
gs://swfz-timetracker/toggl/month=2020-04-01/workspace=work/report.json gs://swfz-timetracker/toggl/month=2020-04-01/workspace=private/report.json gs://swfz-timetracker/toggl/month=2020-05-01/workspace=work/report.json gs://swfz-timetracker/toggl/month=2020-05-01/workspace=private/report.json
BigQueryへの自動読み込み時にパーティションも張っておきたいためディレクトリ名はmonth=2020-05-01のようにしています
BigQueryへのロード
bq load --source_format=NEWLINE_DELIMITED_JSON --replace --autodetect --hive_partitioning_mode=AUTO --hive_partitioning_source_uri_prefix=gs://swfz-timetracker/toggl/ toggl.times gs://swfz-timetracker/toggl/*
これもコマンドたたくだけです
- source_format
- GCSから読み込む場合は
NEWLINE_DELIMITED_JSONとなる- 改行区切りのJSON
- GCSから読み込む場合は
{"hoge": 1, "fuga": 2} {"hoge": 2, "fuga": 3}
replace
- GCSへ配置するファイルは基本的に名前を指定して上書きしていくのでload時には置換を指定する
autodetect
- schema自動検出を有効にする
hive_partitioning_mode
- パーティションスキーマ検出モード
- 特別なことはしてないので
AUTOで指定
hive_partitioning_source_uri_prefix
- 指定したprefix以下でパーティションキーを認識してくれるようになる
参考
外部パーティション分割データの読み込み | BigQuery | Google Cloud
今回だとmonth,workspaceでパーティションが張られる
費用に関して
BigQueryとGCSは有料ではありますが、この程度のデータ量であればほぼ料金がかからないです
4ヵ月ほどデータを貯めている現在で総データ量が600K程度なのでほぼ料金は気にせず使えます
どうしても気になるのであればスプレッドシートなどに転記してDataPortalからクエリ投げるという方法もあるかと思います
DataPortalで可視化
ここまでの作業を定期的に実行させるようにしてしまえば自動的にレポートデータが更新されていきます
あとはグラフを作っていくだけです
グラフでは0.5h刻みくらいで見れればよいと判断しています
なので次のように0.5h刻みに丸める計算フィールドを用意しています
- durはmilliseconds

余談
Togglでの記録のとり方
workspaceを3つ作ってます
- work
- 仕事での時間
- 粒度は試行錯誤中
- 会議
- 作業
- Input
- 雑多(メッセージチェック)
- default
- 睡眠時間
- private
- プライベート(一人の時間)でのコーディングや読書、ネットサーフィンなどに当てている時間
- 漫画やアニメ、ゲームとかは含めてない(そもそもあまりやらない)
tagは1レコード1タグにしています
※お手軽運用なので複数タグをつけると集計結果がタグのぶんだけ加算されてしまうはずです
ちゃんとやるならタグも考慮していろいろ手を入れる必要があると思います
BigQueryでなんとかできる気もしますがまだ調べられていないので別の機会に試してみようと思っています
結果
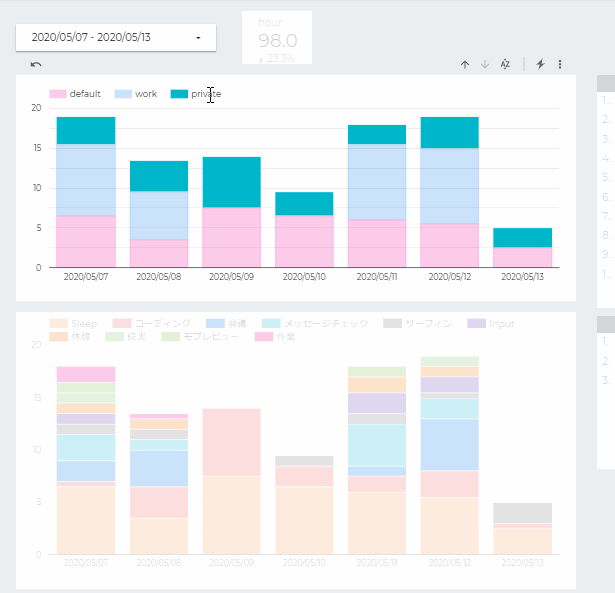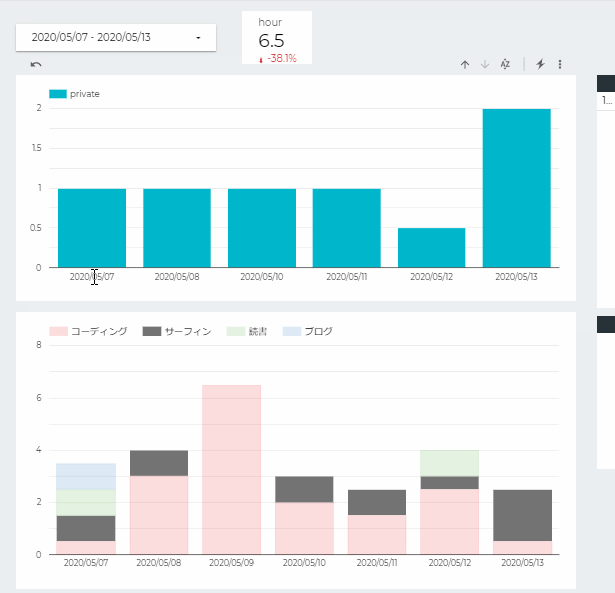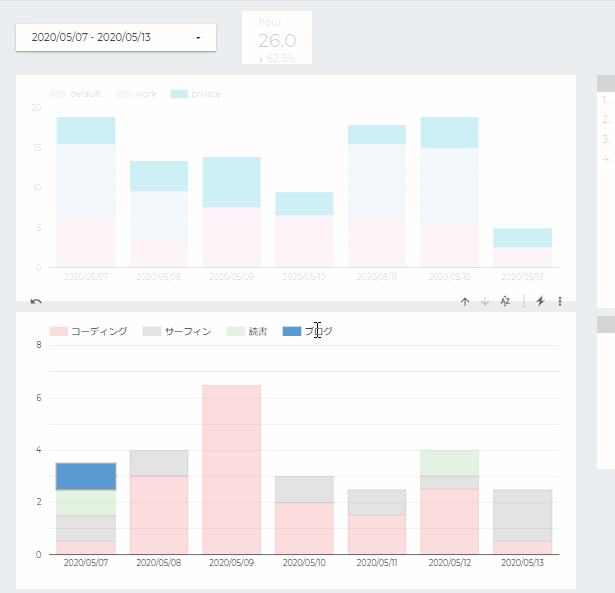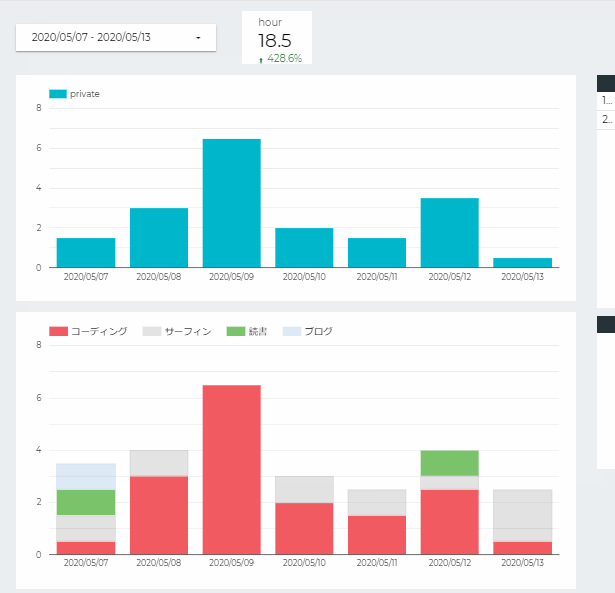
複数のグラフ間で同じデータソースを参照していればインタラクティブフィルタが使えます
特定の項目をクリックし(Ctrl+Clickで複数選択も可)関連するデータを絞り込んで他のグラフで表示できるので見やすいです
まとめ
このくらいのデータ量であればBigQueryでなくてもよい気がするが今回は練習ということで使ってみました
- GCS+BigQuery+DataPortalの組み合わせはおとてもお手軽
- とりあえずGCS突っ込んであとはクエリで頑張ってもよいし整形処理入れてもよい
- 何かしらデータ取る場合の可視化手段の初手として有用
- グラフ化部分でサーバを用意する必要がないので運用が楽
- DataPortalはTableauなどの有償ツールに比べるとやはり見劣りする部分もあるので使い込みたい場合はそのときまた検討でよいと思う
以前ほぼ同じ内容でS3 + Athena + Redashでも可視化してみたがやはりRedash用にサーバを用意しなくてはならず微妙だなーと思ってました
Redashはクエリ書ける、接続先データソースが多いなどメリットもあるもののDataPortalの手軽さを知ってしまうとどうしても軽い感じならDataPortalでやってしまおうという感覚になりました
あとインタラクティブフィルタが便利!
とても楽に可視化ができるのでどんどん使っていきたいところですね
