とりあえず触ってみようという感じのノリで使ってみた
Python自体初学なので勉強含めてやってみる
Cloud Dataflow
Dataflow: ストリーム処理とバッチ処理 | Google Cloud
ETLなどで使う感じ
AWSだとGlueみたいな感じの立ち位置なのかな?
中身はApache BeamでDataflowではApache Beamの実行環境のプロビジョニングをフルマネージドで行ってくれる
また、Beam自体は同じコードでストリーム処理とバッチ処理を両方対応できるらしい
今回はバッチで試してみる
ローカルで試してみる
まずはexampleのwordcountから
https://github.com/apache/beam.git
からチェックアウトしてローカルで実行してみる
ソースは下記
beam/wordcount.py at master · apache/beam
# # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # """A word-counting workflow.""" # pytype: skip-file import argparse import logging import re import apache_beam as beam from apache_beam.io import ReadFromText from apache_beam.io import WriteToText from apache_beam.options.pipeline_options import PipelineOptions from apache_beam.options.pipeline_options import SetupOptions class WordExtractingDoFn(beam.DoFn): """Parse each line of input text into words.""" def process(self, element): """Returns an iterator over the words of this element. The element is a line of text. If the line is blank, note that, too. Args: element: the element being processed Returns: The processed element. """ return re.findall(r'[\w\']+', element, re.UNICODE) def run(argv=None, save_main_session=True): """Main entry point; defines and runs the wordcount pipeline.""" parser = argparse.ArgumentParser() parser.add_argument( '--input', dest='input', default='gs://dataflow-samples/shakespeare/kinglear.txt', help='Input file to process.') parser.add_argument( '--output', dest='output', required=True, help='Output file to write results to.') known_args, pipeline_args = parser.parse_known_args(argv) # We use the save_main_session option because one or more DoFn's in this # workflow rely on global context (e.g., a module imported at module level). pipeline_options = PipelineOptions(pipeline_args) pipeline_options.view_as(SetupOptions).save_main_session = save_main_session # The pipeline will be run on exiting the with block. with beam.Pipeline(options=pipeline_options) as p: # Read the text file[pattern] into a PCollection. lines = p | 'Read' >> ReadFromText(known_args.input) counts = ( lines | 'Split' >> (beam.ParDo(WordExtractingDoFn()).with_output_types(str)) | 'PairWIthOne' >> beam.Map(lambda x: (x, 1)) | 'GroupAndSum' >> beam.CombinePerKey(sum)) # Format the counts into a PCollection of strings. def format_result(word, count): return '%s: %d' % (word, count) output = counts | 'Format' >> beam.MapTuple(format_result) # Write the output using a "Write" transform that has side effects. # pylint: disable=expression-not-assigned output | 'Write' >> WriteToText(known_args.output) if __name__ == '__main__': logging.getLogger().setLevel(logging.INFO) run()
pip install apache-beam python ./beam/sdks/python/apache_beam/examples/wordcount.py --input ./beam/README.md --output word-count --runner DirectRunner
- 結果
Licensed: 1 to: 10 the: 36 Apache: 12 Software: 1 Foundation: 1 ASF: 2 under: 5 one: 1 or: 9 more: 2 contributor: 1 license: 1 agreements: 1 See: 4 NOTICE: 1 file: 3 distributed: 6 ..... ..... ..... .....
--runner DirectRunnerでローカル実行できる
とても簡単
中身を読む
オプションの受け渡し
読んでいくとサンプルで動かした--input,--outputはスクリプト側で用意したオプション
def run(argv=None, save_main_session=True): ... ... known_args, pipeline_args = parser.parse_known_args(argv)
argparseのparse_known_argsがargparseで定義したオプションとそれ以外のオプションを分けて代入してくれる
pipeline_argsに代入されたオプション(例だと--runner)は次のコードでbeamのオプションとして渡される
pipeline_options = PipelineOptions(pipeline_args) pipeline_options.view_as(SetupOptions).save_main_session = save_main_session p = beam.Pipeline(options=pipeline_options)
なのでargparseで定義したオプション以外のオプションはbeamのオプションとしてそのまま渡せるようになっている
この方法はおもしろいなと思った、Wrapperなどを作るときに使えそう
パイプライン処理
p = beam.Pipeline(options=pipeline_options) lines = p | 'read' >> ReadFromText(known_args.input) counts = ( lines | 'split' >> (beam.ParDo(WordExtractingDoFn()).with_output_types(unicode)) | 'pair_with_one' >> beam.Map(lambda x: (x, 1)) | 'group' >> beam.GroupByKey() | 'count' >> beam.Map(count_ones))
pはPipelineオブジェクトでそこからパイプで次の処理を書いていく
パイプで次の処理に流すと戻り値がPCollectionになる
PCollectionにさらにパイプで次の処理に流すということができるのでどんどん処理をつなげていくことができる
サンプルの|の後single quoteで囲っている箇所で処理に名前をつけられる
DataflowのGUI上では次ような感じで表示される

変換処理は関数やクラスを定義して渡してもよいしlambdaで書いても大丈夫
実際にちょっと変更して動かしてみたりすると理解しやすいかも
書いてみるとRxJSでごちゃごちゃやる感覚に近く「これはうっかりするとメンテナンスがつらいやつかもなー」などと思ったりした
デプロイ
最初CLIでデプロイどうやるんだって思っていたがそもそもbeam自体の --runnerオプションで実行環境を指定するのでどこでコマンドを打つかを決めるだけだった
なので本番環境の場合はどこでコマンド実行するというのを決めたらそこにソース上げてPythonコマンドでスクリプトをたたくだけでよい
runnerに関しては種類が結構あり、それぞれ対応しているメソッドが違ったりするようなので次の表で確認する必要がある
ローカルで実行する場合はDirectRunner,Dataflow上で実行する場合はDataflowRunner
今まで経験したことのないパターンだったのでちょっと戸惑ったがこれはこれでよい気がする
書いてみる
書いたのはシェアなどの数を最終的にBigQueryに突っ込むコードを書いた
結構長くなってしまったので解説などは割愛する
shared-count/aggregator.py at master · swfz/shared-count
今回は↑を書くにあたってのTipsを書いていく
GCSからの読み込み
ReadFromTextでGCSのURLを指定すればOK
data = p | 'READ' >> ReadFromText('gs://hoge/fuga/*')
テキスト読み込みでは改行区切りの単位でデータが扱われる
JSONL(1行1行がJSON)のフォーマットでGCSへ置いて毎度json.loads(str)でパースする
BigQueryへの書き込み
このあたりを参考にとりあえずいれてみる
- sample.py
import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions p = beam.Pipeline(options=PipelineOptions()) quotes = p | beam.Create([ { 'source': 'Mahatma Gandhi', 'quote': 'My life is my message.' }, { 'source': 'Yoda', 'quote': "Do, or do not. There is no 'try'." }, ]) table_spec = 'hoge-000000:sample.sample' table_schema = 'source:STRING, quote:STRING' quotes | beam.io.WriteToBigQuery( table_spec, schema=table_schema, write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE, create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED ) p.run().wait_until_finish()
はいった
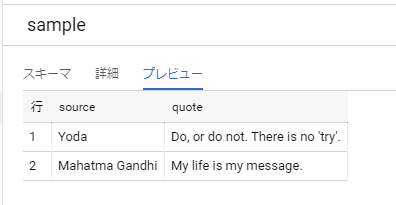
ドキュメントにもあるがBigQueryのテーブルスキーマを定義する必要がある模様
よしなにやってくれるわけではないみたいで少し面倒だった
遭遇したエラーなど
権限エラー
DataflowRunnerを使用中に発生した
サービスアカウントに対象の操作権限がないパターン
Jobの実行にはdataflow.jobs.createの権限が必要
"(3b95fecb5f54e1ed): Could not create workflow; user does not have write access to project: hoge-000000 Causes: (3b95fecb5f54e142): Permission 'dataflow.jobs.create' denied on project: 'hoge-000000'",
実行環境のマネージをするためComputeEngineへのアクセスも必要
"(84ad1a753d8294d1): The workflow could not be created. Causes: (84ad1a753d8296f2): Unable to get machine type information for machine type n1-standard-1 in zone us-central1-f because of insufficient permissions. Please refer to https://cloud.google.com/dataflow/access-control#creating_jobs and make sure you have sufficient permissions.",
モジュール読み込み
File "fuga.py", line 29, in process NameError: name 'pvalue' is not defined [while running 'DivideService/ParDo(ExtractService)'] Note: imports, functions and other variables defined in the global context of your __main__ file of your Dataflow pipeline are, by default, not available in the worker execution environment, and such references will cause a NameError, unless the --save_main_session pipel ine option is set to True. Please see https://cloud.google.com/dataflow/faq#how-do-i-handle-nameerrors for additional documentation on configuring your worker execution environment.
save_main_sessionを有効にしろっていわれているようなので次の修正を行った
- def run(argv=None, save_main_session=False): + def run(argv=None, save_main_session=True):
importをどこに書くかでも解決できる模様
自作モジュールの読み込み
modules/bq_schema.pyというファイルを用意してBigQueryのテーブルスキーマを読み込んでいた
ローカル実行時はうまく言っていたがDataflow上で実行するとエラーが発生した
ModuleNotFoundError: No module named 'bq_schema'
__init__.pyを設置すればよいらしい
modulesディレクトリに__init__.pyを設置、実行ディレクトリにsetup.pyを設置して対応した
このあたり正直良く理解できてないけどPythonでは慣習なのかな
python - Dataflow/apache beam: manage custom module dependencies - Stack Overflow
Managing Python Pipeline Dependencies
- 参考
Python の init.py とは何なのか - Qiita
BigQueryスキーマ
2020-04-13 12:49:27.448 JSTWorkflow failed. Causes: S10:WriteBookmarkToBigQuery/WriteToBigQuery/NativeWrite failed., BigQuery import job "dataflow_job_18028366815374964034" failed., BigQuery creation of import job for table "bookmark" in dataset "blog_data" in project "hoge-000000" failed., BigQuery execution failed., HTTP transport error: Message: Invalid value for: ARRAY<STRING> is not a valid value HTTP Code: 400
配列データを入れる必要があったのでtype=ARRAY<STRING>と書いたら怒られたのでtype=STRING,mode=REPEATEDとして対応した
まとめ
とりあえず動かしてみて実際に使ってみた
ローカル実行がとても楽
- runnerオプションで処理自体の実行場所を指定する
- そのためローカルで実行したとしても処理自体は
Dataflowで処理するみたいな使い方ができる - あくまでDataflowはbeamの実行環境を提供するだけ
- そのためローカルで実行したとしても処理自体は
- runnerオプションで処理自体の実行場所を指定する
Pythonの基礎教養がない状態でやったので結構基礎周りでもつまずいた
- 勉強になった、ある程度読めるようにはなった
この手のサービスを使って効果が出そうなほどの大量データを処理するみたいなパターンでは使えてないため今後試してみたい
- ストリーム処理といえば自分はRx系のイメージがあったので流れは理解しやすかった
- 細かな挙動までは把握できていないので今後調べる
